- This topic has 25 replies, 2 voices, and was last updated 4 years, 8 months ago by
Vadim Smirnov.
-
AuthorPosts
-
June 28, 2021 at 1:18 am #11579
So i tried it with multiple systems with different CPUs, baremetal and VM, and the results are the same.
Running the SNI inspector/Dnstrace x64 versions on a win10x64 will reduce the file transfer speed through shares around 50%
for example 70MB/s -> 30MB/s.
Is there any fix available for this? or there is no solution?
Although i should mention that on some high end CPUs such as i7 7700k the reduction was around 10-15%, but most of average customers don’t have these so we have to assume the worst case scenario where they have an average or low end CPU.
June 28, 2021 at 1:18 am #11580Also i would be grateful if you can test this yourself on different systems as well, specially with low end and average CPUs and check the results.
June 28, 2021 at 2:10 am #11584I have tested 8 years old Core i3-3217U (I don’t have anything slower with Windows installed) sending file to another machine over SMB with and without dnstrace running. Here are the results:
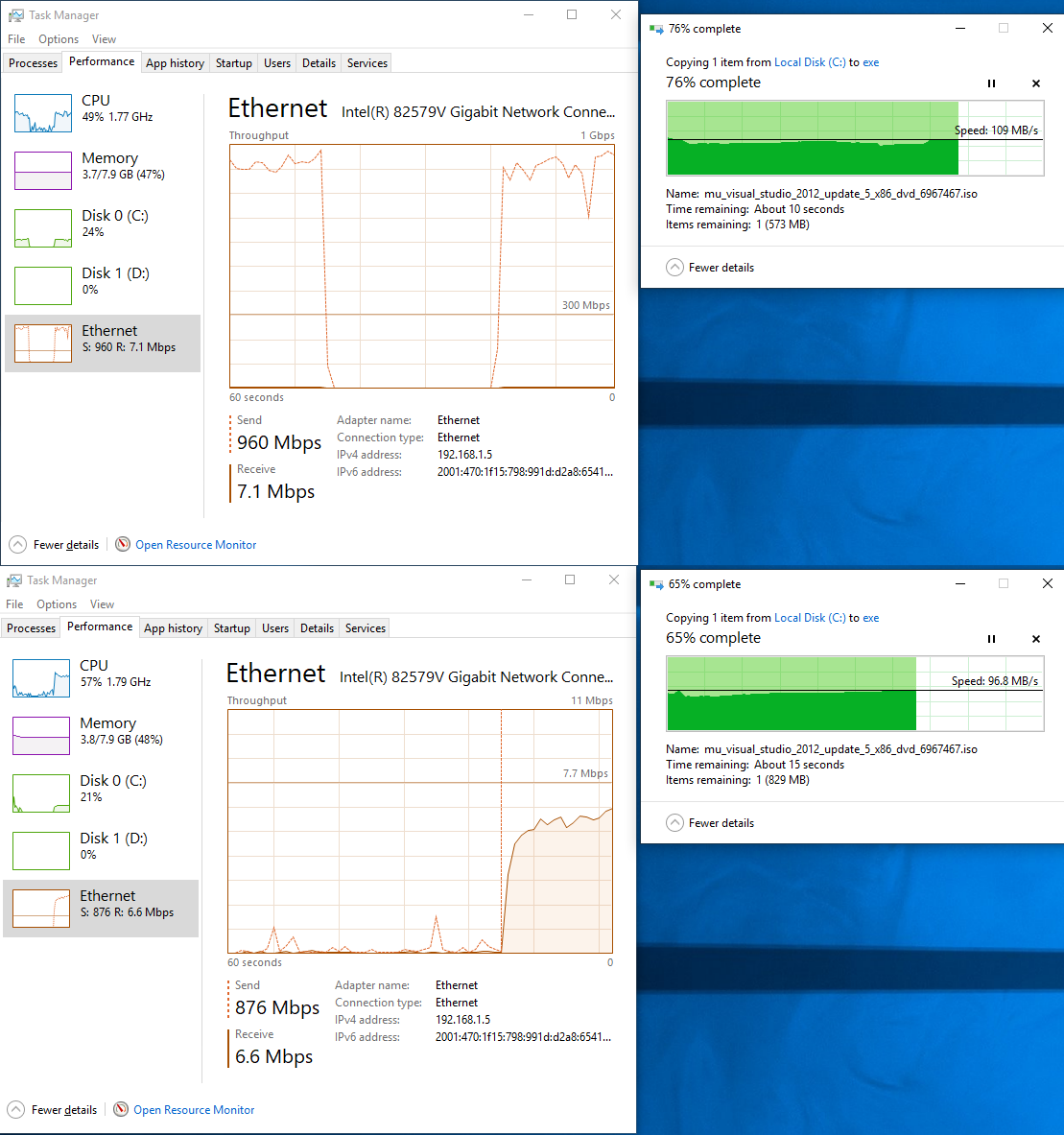
You can notice some slow down (8-9%) but it is not close to the 50% throughput reduction you have reported. What was the bottleneck in your tests?
June 28, 2021 at 2:39 am #11585P.S. An example, when I have tested the same machine but the target file was located on the HDD (on the screenshot above the file is on the SSD) I have had about 3x-4x slower throughput with 100% HDD load.
June 28, 2021 at 4:12 am #11586This is the result on a i7-2600 @ 3.4GHz Win10x64:
100MB/s -> 40MB/s
CPU: 52%
Memory: 30%
Disk: 10%So i dont know which one is the bottleneck, but when i turn off the dnstrace it goes back to 100MB/s and CPU usage goes to 40% but thats it..
Everything is latest version, i even used the 64 bit compiled tools from the website and didn’t compile them myself to make sure nothing is wrong.
June 28, 2021 at 5:18 am #11588This is the result on a i7-2600 @ 3.4GHz Win10x64:
100MB/s -> 40MB/s
CPU: 52%
Memory: 30%
Disk: 10%The test system was a receiver, right?
In my test above I’ve been sending the file from the test system. When I have changed the direction, I have experienced more noticeable throughput degradation.
What is important here is that in both cases it was a maximum performance achievable by single threaded dnstrace application (Resource Monitor showed 25% CPU load over 4 vCPU). This is the bottleneck… Inbound packet injection is more expensive than outbound and this explains the performance/throughput difference for inbound/outbound traffic I experience on i3-3217U. On the other hand Ryzen 7 4800H single-threaded performance is good enough to not to have any throughput degradation at all regardless of the traffic direction.
Worth to note that Fast I/O won’t be of much help here, it was primarily designed for the customer who uses the driver in the trading platform and needed a fastest possible way to fetch the packet from the network to the application bypassing Windows TCP/IP stack.
First idea to consider is improve dnstrace performance by splitting its operations over two threads, e.g. one thread to read packets from the driver and second thread to re-inject them back.
I also think some optimization is possible for the packet re-injection either. E.g. scaling packet re-injection over all available vCPUs in the kernel. Though, it is not that easy as it sounds, breaking packet order in the TCP connection may result re-transmit and other undesired behavior. So, maybe adding Fast I/O for re-injection could be a better choice (currently packets are re-injected in the context of dnstrace, in case of Fast I/O they would be re-injected from the kernel thread).
June 28, 2021 at 5:29 am #11589Yes, in my case i was receiving the file from a remote server.
First idea to consider is improve dnstrace performance by splitting its operations over two threads, e.g. one thread to read packets from the driver and second thread to re-inject then back.
Are you sure this will help much? because in this way i guess we have to have a seperate link list for the packets that are needed to get re inject, and the reader thread needs to insert every received packet into this, which i don’t see why would this improve the performance much. seems like its mostly the same as having it all in one thread?
I think we need to focus on SMB to solve this issue, i found an OSR thread here:
https://community.osr.com/discussion/290695/wfp-callout-driver-layer2-filtering
Which has a important part in it:
However, I am encapsulating packets and needed the ability to be able to create NBL chains in order to improve performance when dealing with large file transfers and the like (i.e. typically for every 1 packet during an SMB file transfer one needs to generate at least 2 packets per 1 original packet because of MTU issues)
Thoughts?
June 28, 2021 at 6:24 am #11590Here is the CPU breakdown of SMB download:
Function Name Total CPU [unit, %] Self CPU [unit, %] Module Category
|||||| – CNdisApi::SendPacketsToMstcp 2858 (56.58%) 3 (0.06%) dnstrace.exe IO | Kernel
|||||| – CNdisApi::SendPacketsToAdapter 1495 (29.60%) 2 (0.04%) dnstrace.exe IO | Kernel
|||||| – CNdisApi::ReadPackets 349 (6.91%) 6 (0.12%) dnstrace.exe IO | KernelAs you may notice splitting reading and re-injection does not make much sense, but splitting SendPacketsToMstcp and SendPacketsToAdapter over two threads definitely will have an effect.
I can’t see how the OSR post can be related, the author problem is about repackaging packets due to the reduced MTU.
June 28, 2021 at 6:30 am #11591I think 3 threads are good to go:
- ReadPackets thread which forms re-injection lists, signals re-inject threads and waits the re-inject to complete or even better proceeds to read using secondary buffers set
- SendPacketsToMstcp thread waits for ReadPackets signal, re-injects, notifies ReadPackets thread and returns to wait
- SendPacketsToAdapter thread waits for ReadPackets signal, re-injects, notifies ReadPackets thread and returns to wait
June 28, 2021 at 3:15 pm #11592P.S. BTW, if you don’t need the SMB traffic to be processed in user mode then you could load the filter into the driver to pass it over without redirection.
October 21, 2021 at 6:37 pm #11828P.P.S. I have performed some research and significantly improved packets re-injection performance in v3.2.31. Thanks for reporting this. By the way building driver with Jumbo frames support could improve the performance over 1 Gbps wire even further.
-
AuthorPosts
- You must be logged in to reply to this topic.